Local Ollama running Mixtral LLM with LLamaIndex, loaded with personal tweet context

Ollama allows to run large language models locally. I was excited to learn about Mixtral, an open model, now available through LLamaIndex with Ollama, explained in this blog tutorial. The example to load my own tweets to ask questions in this unique context is fascinating.
After running Ollama, and using LlangChain to ask some questions in my Ops In Dev newsletter in December 2023, this is the next learning step.
Requirements
Ollama Setup
Install Ollama on macOS, and ensure that you have ~50 GB storage available for different LLM tests. Since Mixtral requires 48 GB RAM to run properly, I decided to use the smaller Mistral 7B model for my first tests. You can open a prompt in Ollama by running the following command:
ollama run mistral This will download the LLM locally, and might take a while.
Python programs
Hello #1
Start by testing whether the LLM is running, and fire a question. (source)
# Just runs .complete to make sure the LLM is listening
from llama_index.llms import Ollama
llm = Ollama(model="mixtral")
response = llm.complete("What is the history of LEGO?")
print(response)Hello #2 - index Twitter/X tweets and ask questions
Follow the code snippet (source) and implement the following steps:
- Import all necessary libraries, and load the tweets JSON file into memory. (Note: This required changes to the original source code, see the end of this blog post)
from pathlib import Path
import qdrant_client
from llama_index import (
VectorStoreIndex,
ServiceContext,
)
from llama_index.llms import Ollama
from llama_index.storage.storage_context import StorageContext
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_hub.file.json import JSONReader
# load the JSON off disk
loader = JSONReader()
documents = loader.load_data(Path('./data/tweets.json'))2. Create a new vector store using a local Qdrant data path. Specify the collection name to tweets - note this name for later when inspecting the qdrant_data directory after running the script.
# initialize the vector store
client = qdrant_client.QdrantClient(
path="./qdrant_data"
)
vector_store = QdrantVectorStore(client=client, collection_name="tweets")
storage_context = StorageContext.from_defaults(vector_store=vector_store)3. Initialize the LLM. It will embed documents locally, thus requiring torch and transformer Python packages. Note that this example uses Mistral instead of Mixtral.
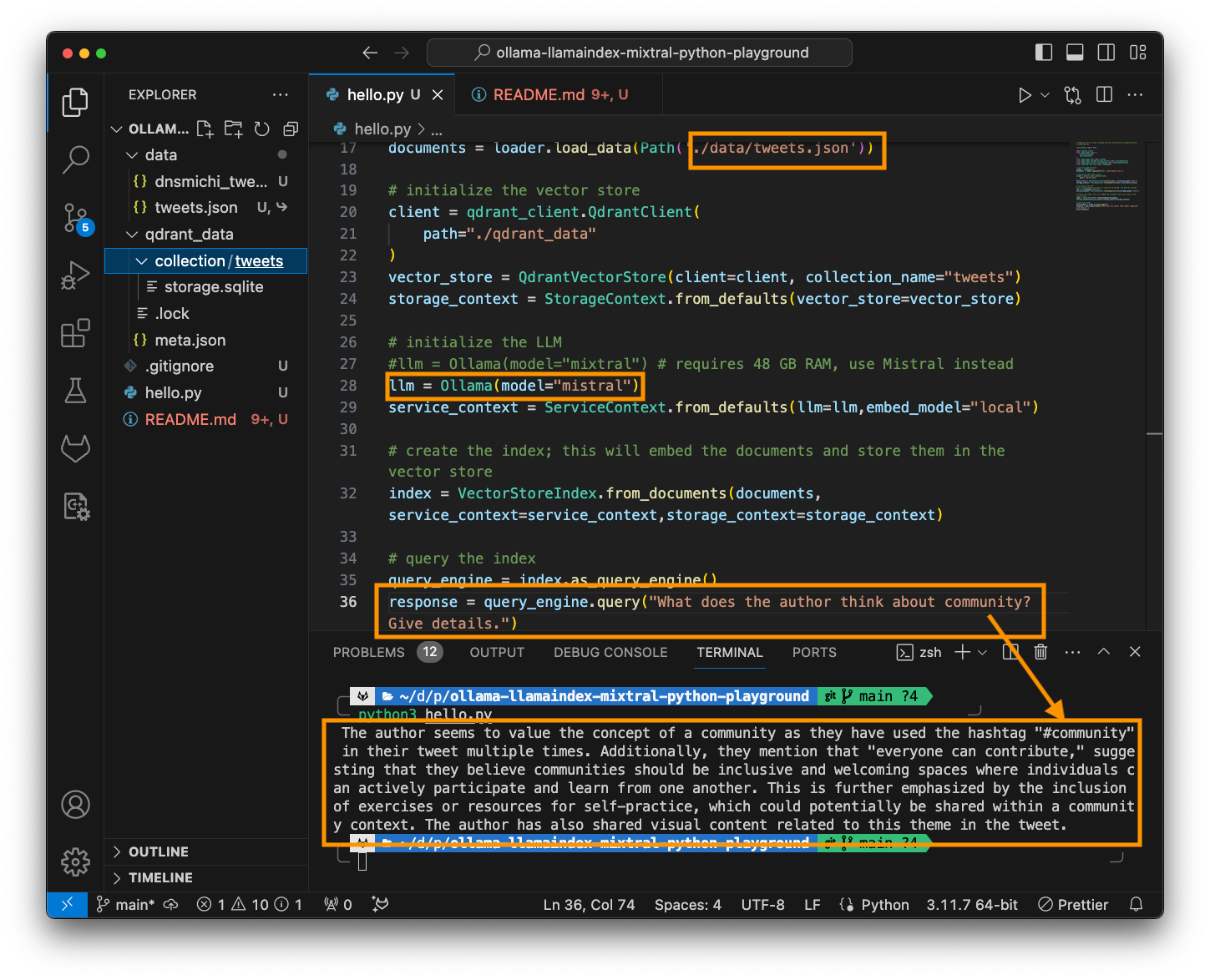
# initialize the LLM
#llm = Ollama(model="mixtral") # requires 48 GB RAM, use Mistral instead
llm = Ollama(model="mistral")
service_context = ServiceContext.from_defaults(llm=llm,embed_model="local")4. Create an index from the tweets as documents, and load them into the vector store.
# create the index; this will embed the documents and store them in the vector store
index = VectorStoreIndex.from_documents(documents,service_context=service_context,storage_context=storage_context)5. Query the index, and ask questions which will be answered based on the loaded tweets context.
# query the index
query_engine = index.as_query_engine()
response = query_engine.query("What does the author think about community? Give details.")
print(response)The full example is located in this GitLab project.
Install Python packages
Install the required Python packages.
pip3 install llama-index qdrant_client torch transformers llama-hubTwitter/X archive
You can request an archive download in your profile settings, but this might take a couple of days. I had an older backup from 2022 laying around, from which I extracted my tweets from 2020.
Unfortunately the tweet archive is not directly JSON, but uses a custom format. I've found these instructions to automate the conversion.
cd data
rsync -I --backup --suffix='.json' --backup-dir='json' --exclude='manifest.js' ./*.js ./\nsed -i -r 's/^window.*\ \=\ (.*)$/\1/' json/*
You can test the converted data sets by installing jq and printing the unique number of tweeted URLs.
cd json/
jq '.[] | .tweet | select(.entities.urls != []) | .entities | .urls | map(.expanded_url) | .[]' tweets.js.json | cut -d'/' -f3 | sed 's/\"//g' | sort | uniq -c | sort -g
216 youtu.be
236 about.gitlab.com
269 buff.ly
348 gitlab.com
1134 twitter.comCopy the converted JSON file into the data/ directory, and modify the symlink to tweets.json.
cd data
rm tweets.json
ln -s your_tweets.json tweets.json Run the program
Open a new terminal in VS Code using cmd shift p - search create new terminal and execute the hello.py file using the local Python interpreter. On macOS, Python can be installed using Homebrew which adds the version suffix to the binary.
python3 hello.py
The author seems to value the concept of a community as they have used the hashtag "#community" in their tweet multiple times. Additionally, they mention that "everyone can contribute," suggesting that they believe communities should be inclusive and welcoming spaces where individuals can actively participate and learn from one another. This is further emphasized by the inclusion of exercises or resources for self-practice, which could potentially be shared within a community context. The author has also shared visual content related to this theme in the tweet.Conclusion
Loading my own tweets, and generating summaries and responses based on this context is a fantastic learning curve.
If you followed the linked tutorial, and ran into execution timeouts, please continue reading below for a detailed analysis on how to fix the problem. The source code in this blog post, and GitLab repository have been updated and tested already.
Additional notes: Debugging download_loader() timeouts
The blog post examples did not work immediately, running into connection timeouts.
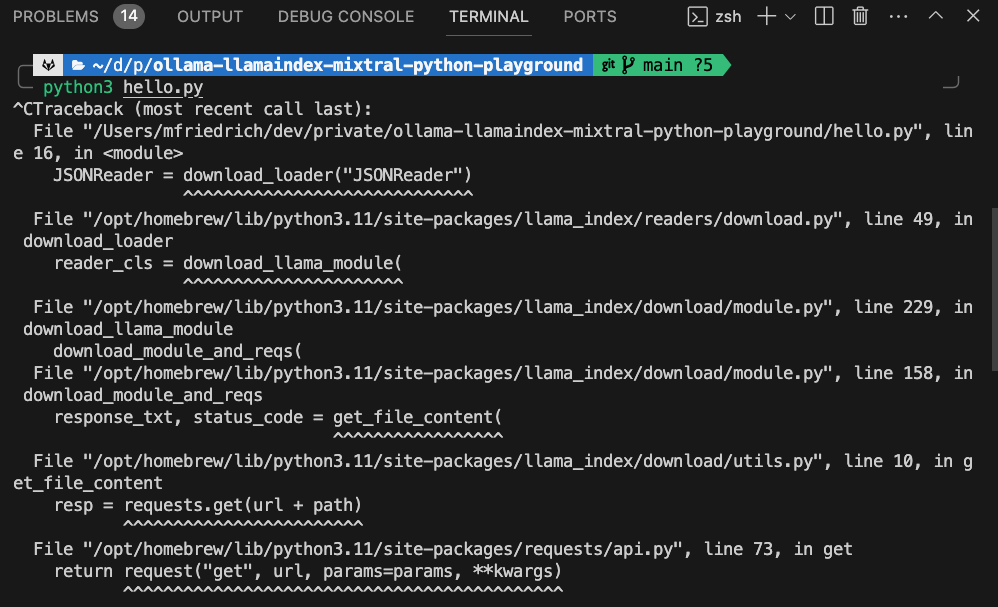
Inspecting the stack trace lead me to the local download.py file from the Python package installed with Homebrew. It noted that the function call for download_loader() is deprecated. The recommendation is to install llama-hub as package.
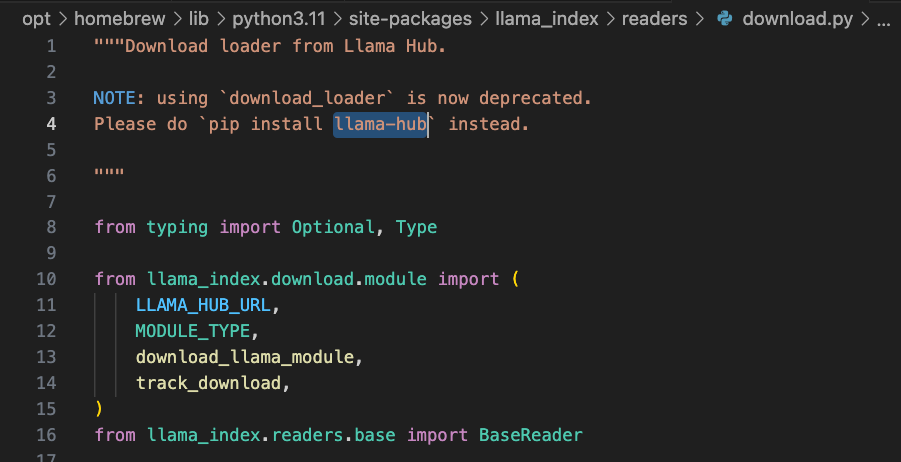
What does it mean to use llama-hub instead? What is a JSONLoader afterall? I opened https://llamahub.ai/ and searched for json, bring up two results.
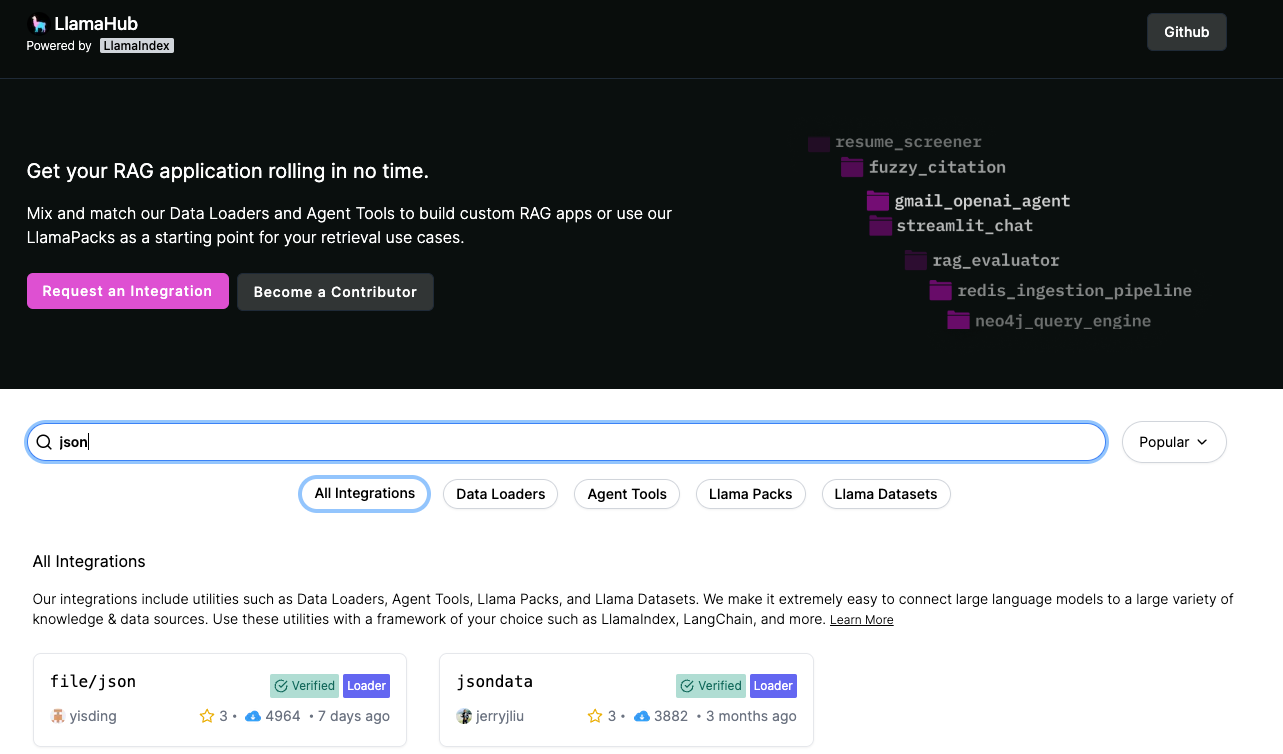
file/json is what I was using and looking for, but the Usage examples still used download_loader().
Taking a step back, I opened the Python example code again. It seems that download_loader() provides two things: 1) Downloads the JSONReader source code, and 2) injects the class into the current scope so it can be executed to load the tweets JSON file as parsed data structure into memory.
from llama_index import (
VectorStoreIndex,
ServiceContext,
download_loader,
)
# load the JSON off disk
JSONReader = download_loader("JSONReader")
loader = JSONReader()
documents = loader.load_data(Path('./data/tweets.json'))
The deprecation note above says to use the llama-hub package instead. Maybe the JSONReader class is available in that package too?
The documentation for llama-hub provides an example for GoogleDocsReader and LLamaIndex.
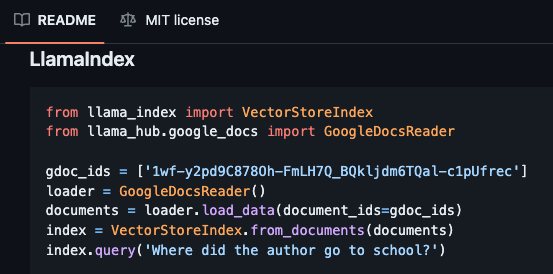
After searching for the JSONReader class, I reconstructed the library import path from the __init__.py file and updated the tweets.json loader code.
from llama_hub.file.json import JSONReader
# load the JSON off disk
loader = JSONReader()
documents = loader.load_data(Path('./data/tweets.json'))The full diff is available here.