Efficient pipelines in GitLab CI/CD: Parallel Matrix Builds + !reference

Today I was diving deeper into GitLab CI/CD Pipeline Efficiency tricks, after I discovered resuable job attributes with !reference last week.
Resource optimization is a big topic, and next to ideas on failing fast, I was looking into more parallelization. Luckily GitLab introduced this feature last year.
Parallel Matrix Builds
Instead of creating multiple jobs for
- RHEL8 and Ubuntu 20
- x64 and x86
which then call the same build scripts and containers, and result in blocking pipelines, it would be much nicer to run them in parallel. We can build it with using the parallel matrix keywords. DISTRIBUTION and ARCH define the arrays.
parallel:
matrix:
- DISTRIBUTION: [rhel8, ubuntu20]
ARCH: [x64,x86]
The great thing about the variables is that they are populated with their values and are mapped into the CI/CD jobs as environment variables. The combined configuration below prints them to show their values - you can do much more with them, e.g. in build scripts for conditional decisions, package names, upload directories, etc.
stages:
- build
- test
build:
stage: build
script:
- echo "Building $DISTRIBUTION on $ARCH"
parallel:
matrix:
- DISTRIBUTION: [rhel8, ubuntu20]
ARCH: [x64,x86]
test:
stage: test
script:
- echo "Testing $DISTRIBUTION on $ARCH"
parallel:
matrix:
- DISTRIBUTION: [rhel8, ubuntu20]
ARCH: [x64,x86]
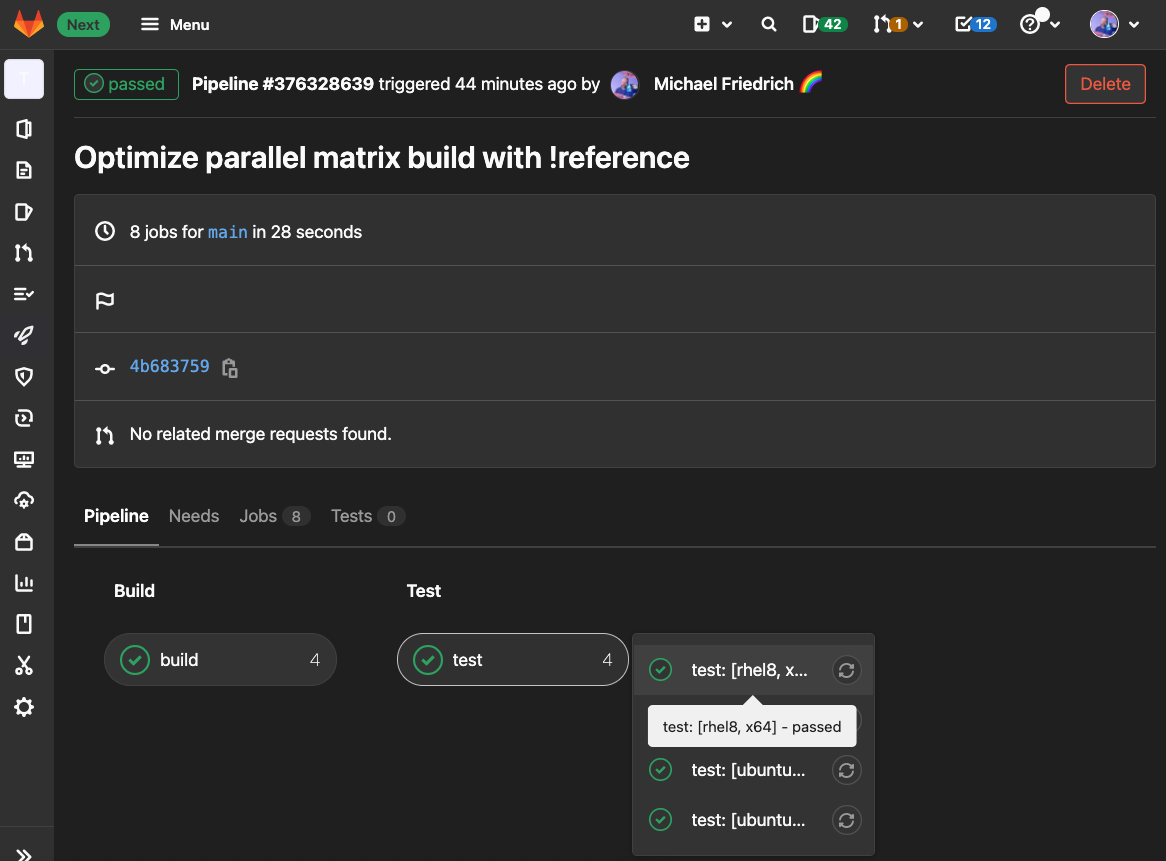
Works :)

As a developer, you spot repeating blocks
2 times the definition of the variable values. Let's imagine we copy paste everything into more jobs for staging and deployments later - someone removes a deprecated distribution, and misses a location. Bingo, happy pipeline debugging.
Variable assignment from global doesn't work unfortunately. Since I learned that !reference allows to reuse existing job attributes such as script and rules (the latter was added in 14.3), I decided to try it with parallel too.
!reference + parallel:matrix?
Define a template job called .parallel and add the matrix attribute in there.
.parallel:
parallel:
matrix:
- DISTRIBUTION: [rhel8, ubuntu20]
ARCH: [x64,x86]
Then use !reference [<job template name>,<attribute name>] to merge it into the other jobs with the parallel attribute.
stages:
- build
- test
.parallel:
parallel:
matrix:
- DISTRIBUTION: [rhel8, ubuntu20]
ARCH: [x64,x86]
build:
stage: build
script:
- echo "Building $DISTRIBUTION on $ARCH"
parallel: !reference [.parallel,parallel]
test:
stage: test
script:
- echo "Testing $DISTRIBUTION on $ARCH"
parallel: !reference [.parallel,parallel]
UN-BE-LIEV-ABLE. IT WORKS.

More pipeline efficiency tricks soon. Watch this space and follow me on social.
Update 2021-09-24: Simon shared a great thought on Twitter.
Is there a non obvious benefit from reference compared to extend? in this case the parallel block most likely will not be altered or needs an addition, so i would also be fine using `extends`. i am just curious :D
— Simon Schrottner (@aepfli) September 24, 2021
Extends instead of !reference?
Remember the mistake I made with extends to override script - I was thinking about that. Using extends is an easier solution, that's correct. I'll share a thought on merge strategies further below, and why I think !reference has a place on the table.
Let's build the above solution with using extends:
stages:
- build
- test
.parallel:
parallel:
matrix:
- DISTRIBUTION: [rhel8, ubuntu20]
ARCH: [x64,x86]
build:
extends: .parallel
stage: build
script:
- echo "Building $DISTRIBUTION on $ARCH"
test:
extends: .parallel
stage: test
script:
- echo "Testing $DISTRIBUTION on $ARCH"

Select specific attributes with !reference vs. extends merge strategies
One difference with !reference is that you control to only inherit one specific job attribute into the current scope. extends merges all attributes, and there is a certain merge strategy involved:
You can use extends to merge hashes but not arrays. The algorithm used for merge is “closest scope wins,” so keys from the last member always override anything defined on other levels.Meaning to say, script gets overridden but variables gets merged. If someone adds variables into the job template, all jobs extending it will inherit and merge. This could lead into unexpected behaviour - especially when this happens by accident.
The following example adds variables and script into the job template, and variables next to script into the jobs. Would you expect that the ENVIRONMENT variable available in jobs?
stages:
- build
- test
.parallel:
variables:
ENVIRONMENT: prod
script:
- echo "Installing dependencies"
parallel:
matrix:
- DISTRIBUTION: [rhel8, ubuntu20]
ARCH: [x64,x86]
build:
extends: .parallel
stage: build
variables:
OPTIMIZE: 1
script:
- echo "Building $DISTRIBUTION on $ARCH"
test:
extends: .parallel
stage: test
variables:
OPTIMIZE: 0
script:
- echo "Testing $DISTRIBUTION on $ARCH"
The merged YAML view in the pipeline editor helps with debugging. This feature is relatively new, so not everyone may know about it. 💡

The variables hash gets merged, script was overridden. In that case, you might want to use !reference with script to solve it.
stages:
- build
- test
.parallel:
variables:
ENVIRONMENT: prod
script:
- echo "Installing dependencies"
parallel:
matrix:
- DISTRIBUTION: [rhel8, ubuntu20]
ARCH: [x64,x86]
build:
extends: .parallel
stage: build
variables:
OPTIMIZE: 1
script:
- !reference [.parallel,script]
- echo "Building $DISTRIBUTION on $ARCH"
test:
extends: .parallel
stage: test
variables:
OPTIMIZE: 0
script:
- !reference [.parallel,script]
- echo "Testing $DISTRIBUTION on $ARCH"
Or avoid mixing extends and only use !reference to visually aid the flow what is merged. That way variables are not inherited if not explicitly specified.
stages:
- build
- test
.parallel:
variables:
ENVIRONMENT: prod
script:
- echo "Installing dependencies"
parallel:
matrix:
- DISTRIBUTION: [rhel8, ubuntu20]
ARCH: [x64,x86]
build:
#extends: .parallel # May merge additional variables
stage: build
variables:
OPTIMIZE: 1
script:
- !reference [.parallel,script]
- echo "Building $DISTRIBUTION on $ARCH"
parallel: !reference [.parallel,parallel]
test:
#extends: .parallel # May merge additional variables
stage: test
variables:
OPTIMIZE: 0
script:
- !reference [.parallel,script]
- echo "Testing $DISTRIBUTION on $ARCH"
parallel: !reference [.parallel,parallel]

Conclusion v2
Both extends and !reference have their advantages. I recommend that you evaluate and practice both strategies for your CI/CD workflows, and document a code style for CI/CD configuration for your team.
I've added the thoughts and feedback above into practical workshop exercises, which will be released later this year. Thanks Simon! :)